


GPT的运作方式是这样的,它是一个建立在庞大数据之上的语言模型chatgpt原理,经过深度训练掌握了丰富的语言知识,能够针对用户的提问,给出恰当且正确的答复,下面我们具体分析其中的原理。
什么是预训练模型
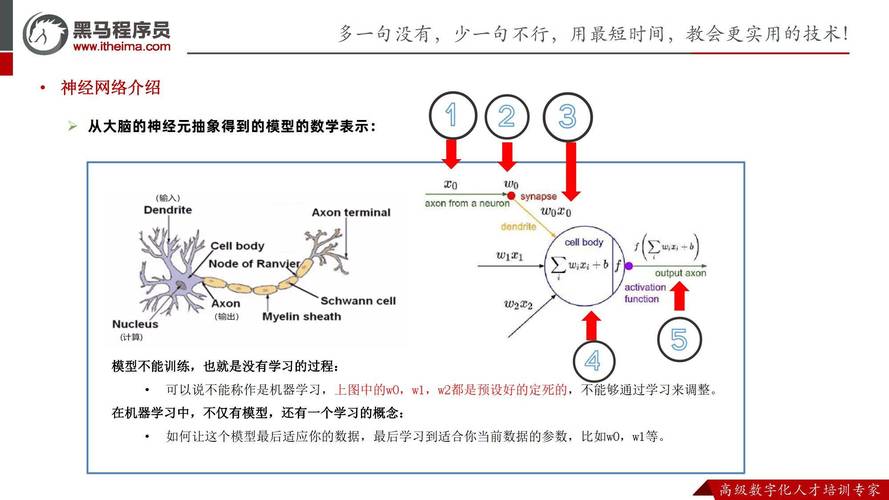
预训练模型是GPT的核心基础部分。它相当于一个极其强大的学习系统chatgpt原理,起初在极为丰富的文本信息中进行训练。这些信息资料涵盖了互联网内容、出版物等多个领域。经过训练,它能够理解语言的构成方式、语法规则以及词汇运用。这类似于人类通过教育不断积累知识,它持续从各种数据中获取信息,为之后的语言运用打下基础。
借助已训练好的模型,可以初步认识多种语言形式。输入疑问时,它迅速从掌握的信息中检索相关内容Ai智能写作助手,接着开展初步的处置和剖析,从而明白我们大致想了解什么。
如何进行微调训练
单纯依靠初始训练是不够的,还必须进行后续的针对性训练。这好比给车辆进行精密的校准Ai写作免费一键生成,针对性训练能让GPT更贴合特定的工作要求和应用环境。在针对性训练环节,会借助一些专门的数据集来优化模型。这些数据集汇集了特定行业的问题与解答。

经过细致的调整,它能够更加准确地应对某些专门领域的询问。例如在医疗、法律等行业,细致的调整能使其提供更加专业的答复。这好比一个人在接受了专门的训练之后,能够在特定的任务中做得更加优秀。
什么是注意力机制
GPT在分析文本时会运用一种核心方法,就是它能够识别出内容里哪些地方比较重要。我们人类看文章时,常常会下意识地把注意力放在关键段落上。GPT的工作原理跟人有点像,它也依靠一种特殊的处理方式来分辨哪些词语和句子需要重点关注。
这样在生成回应时,可以更集中注意力于重要内容,使回应更加精准和切题。比如在应对一段篇幅较长的文字时,它能够迅速识别出主要观点Ai文案生成器,而不是均匀对待,让生成的内容更有价值。
怎样处理上下文信息
GPT的一个突出优势是能够理解前后文。对话里,人们常会提及之前说过的话,它能够记住并联系起来。这好比人与人交谈时,能记住之前讨论的话题,这样沟通才更顺畅。
它借助内部构造来保存并运用背景资料。当我们持续发问时,它能参考之前的交流内容,从而深入理解疑问,提供更加顺滑、更加精准的回应,使谈话更加顺畅,仿佛在与一个记得事情的人交谈。
面临着哪些挑战
GPT的能力很强,不过也存在一些难题。比如,它所依赖的数据在品质和范围上存在不足。如果训练资料存在偏向或不够充分,可能会降低它给出正确答案的可能性。而且,它偶尔也会产生一些表面上看起来有道理,但实际上是错误的内容,这种现象常被称作“幻觉”。
它对于复杂推理和情绪认知的处理能力尚有不足之处,这与人类存在能力短板是相似的,GPT也必须持续地优化和进步。
各位认为GPT今后对于克服这些难题会有多好的效果呢?如果觉得这篇文章有帮助,请记得点个赞并且进行分享。